Sammlungsnetzwerke - Virtueller Sammlungsraum
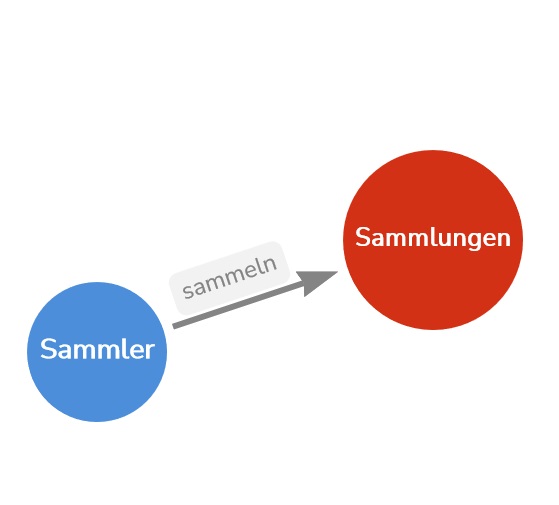
RDF (Resource Description Framework) zählt zu den Säulen des Semantic Web und von Linked Open Data. Das Ziel ist es nicht nur Daten im Web miteinander zu verknüpfen, sondern diese Verknüpfung auch semantisch interpretierbar zu machen. Aussagen werden dabei nach dem Schema Subjekt-Prädikat-Objekt strukturiert wobei Subjekt und Objekt Knoten des Graphen sind und das Prädikat die verbindende Kante. So ließe sich hypothetisch die Aussage Sammler sammeln Sammlungen als ein solches Triple auffassen, und zugleich als Keimzelle einer vernetzten Sammlung. Durch die Verknüpfung mehrerer Triples miteinander entsteht ein komplexer Graph.
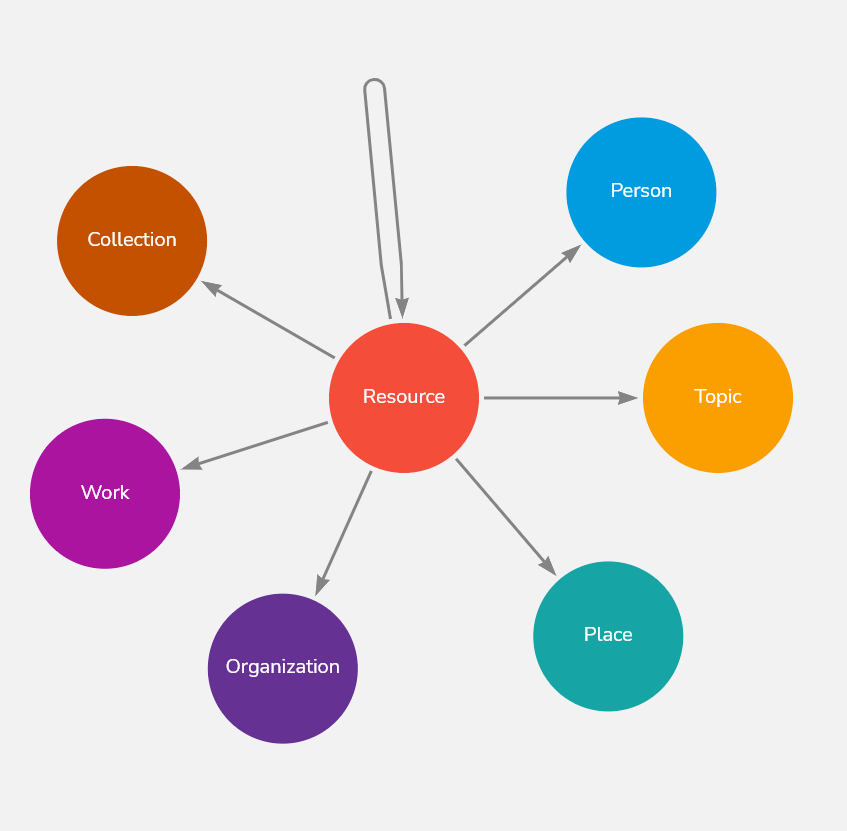
Jede Aussage, die über ein Objekt einer Sammlung oder einen damit verbundenen Akteur getroffen werden kann, lässt sich als Triple in dieses Netzwerk integrieren. Ein Buch hat einen Titel. Eine Person ist geboren an einem Datum. Eine Skizze ist eine Vorstudie für ein Bild. Alle Daten haben so einen Platz in dem Netzwerk und fungieren zugleich als mögliche Anknüpfungspunkte für die weitere Vernetzung. Das Netz, sofern man es als Metapher aus der Fischerei betrachtet, wird sozusagen immer dichter geknüpft. Mit zunehmender Dichte der Aussagen wird zugleich das Wissen über unser kulturelles Erbe aussagekräftiger.
Auf RDF basierende Datenmodellierungen zeigen sehr eindrücklich, dass was wir sonst gerne als einen Datensatz eine Beschreibung eines Objektes ansehen, im Grunde eine Serie von Aussagen ist, welche über diese Informationsressource getroffen werden. Statt eines Datenblocks sind es viele kleine Atome, welche einen Kern (das Objekt, die Person, den Ort) umkreisen, ihn beschreiben und mit ihm verbunden sind. Im Gegensatz zu dieser Form der Modellierung, welche jeder Information einen Knoten im Netzwerk zuweist, gibt es noch ein weiteres verbreitetes Modell, mit welchem Graphen oder Netzwerke technisch beschrieben werden können.
Neben RDF als einer technologische Grundlage, um Daten in vernetzter Form zu speichern, besteht die Möglichkeit Netzwerke in Form von sogenannten Labeled Property Graphen (LPG) zu modellieren. Die Grundstruktur von Graphen (Knoten und Kanten) ist auch hier gegeben. Im Gegensatz zu RDF können sowohl den Knoten als auch den Kanten hier jedoch auch noch weitere Eigenschaften (Properties) gegeben werden. Ein einzelner Knoten mit dem Label Person, kann somit den Namen "Johann Wolfgang von Goethe" ein Geburts- und ein Sterbedatum erhalten. In RDF übersetzt, müsste jede dieser Aussagen in ein eigenes Triple aus zwei Knoten und einer Kante umstrukturiert werden (Person - hat Name - Johann Wolfgang von Goethe, ... - hat Sterbedatum - .... etc.). So ergibt sich eine andere Graphenstruktur und andere Möglichkeiten in der Datenmodellierung. Mittels der Möglichkeit den Links zwischen den Entitäten weitere Eigenschaften zu vergeben, können so auch komplexe Beziehungen sehr kompakt modelliert werden.
RDF oder Labeled-Property-Graph, was ist die beste Lösung um Daten über kulturelle Sammlungen auf einer technischen Basis zu speichern und zu modellieren? Die klassische Antwort ist - wie so oft im Leben - "das kommt drauf an". Jeder der vorgestellten Technologien hat ihre Vor- und Nachteile sowie ihre spezifischen Use Cases und Anwendungslösungen. Im Rahmen des Projektes zum Virtuellen Sammlungsraum, wird es daher auch darum gehen verschiedene Technologien und Möglichkeiten zu evaluieren, um die vernetzten Daten nicht nur in aussagekräftige Netzwerke überführen zu können, sondern auch ein hohes Maß an Interoperabilität mit anderen Datenbeständen und Anwendungen gewährleisten zu können.
Das entwickelte und hier vorgestellte Datenmodell basiert auf dem etablierten Standard CIDOC-CRM, der sich mithilfe von RDF ausdrücken lässt.