Born Digitals
Ziel und Form der Visualisierung
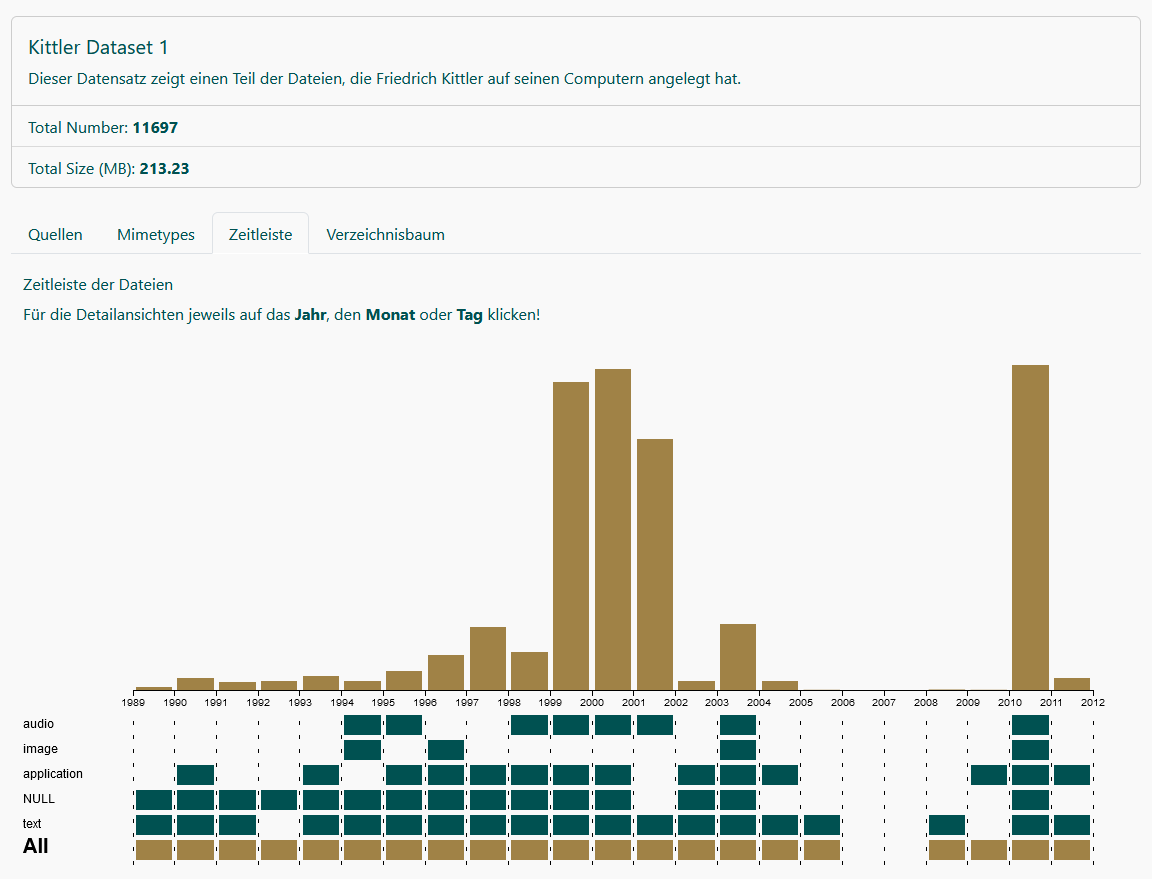
Die Visualisierung des digitalen Nachlasses Friedrich Kittlers soll es dem Forschenden erleichtern, einen Überblick über die große Menge an Dateien zu erhalten und einen Einstieg in die Erforschung kleinerer, einzelner Dateibestände zu finden. Die Visualisierung realisiert unterschiedliche Perspektiven auf den Dateibestand. So werden die einzelnen Dateien, gruppiert nach ihren "Quellen", etwa "od" (optical drive), "hd" (hard disk), und ihren "Mimetypes", etwa "text", "image", "audio", "application", "NULL", mithilfe von Kuchen- und Balkendiagrammen quantitativ visualisiert. Die "Zeitleiste" (s.u.) gibt dem Forschenden einen Einblick in den zeitlichen Verlauf des Bestandes, aufgeschlüsselt nach den Mimetypes der Dateien. Mithilfe einer binären Ansicht lässt sich, zunächst auf die Jahre des Schaffens bezogen, schnell ablesen, ob Kittler Dateien angelegt hat oder nicht. Diese binäre Ansicht lässt sich um Balkendiagramme erweitern, die einen Überblick über die Quantität der Dateien in den einzelnen Jahren gewähren. Auf diese Weise lässt sich der digitale Schaffensprozess Kittlers quantitativ über den Lauf der Jahre ablesen. Durch User-Interaktion kann die beschriebene Darstellung für ein Jahr und dort wiederum für einen Monat bis hin zu den einzelnen Dateien erweitert werden, wodurch ein "Zoomen" hinein in den Bestand bis auf Dateiebene möglich wird. Der "Verzeichnisbaum" zeigt die einzelnen Dateien innerhalb der Verzeichnisstruktur, die Kittler genutzt hat. Die Struktur ist als Graph visualisiert und auf die einzelnen Jahre des Schaffensprozesses abgetragen.