
Rechte und Lizenzen - Digitales Labor
Wie beeinflussen Fragen zu Rechten und Lizenzen den Aufbau häuserübergreifender digitaler Forschungsinfrastruktur?
(Dieser Beitrag erschien im Themenheft "Lizenzangaben und Rechtedokumentationen im Dialog. Datenflüsse nachhatlig gestalten." der Deutschen Nationalbibliothek)
Ausgangslage
Das Deutsche Literaturarchiv Marbach, die Klassik Stiftung Weimar und die Herzog August Bibliothek Wolfenbüttel sammeln, bewahren und erschließen materielle Zeugnisse deutscher und europäischer Kulturgeschichte. Seit dem Jahr 2013 bündeln diese Einrichtungen ihre Forschungsaktivitäten auf Empfehlung des Wissenschaftsrates in einem vom Bundesministerium für Bildung und Forschung geförderten Forschungsverbund, in dessen Rahmen unter anderem digitale Forschungsinfrastruktur aufgebaut wird. In drei Teilprojekten werden Komponenten entwickelt, um bestandsbezogene Forschung von der Erschließung über Analyse- und Auswertungsverfahren bis hin zur Veröffentlichung von Forschungsergebnissen digital zu unterstützen.[1] Die folgende vereinfachte Architekturskizze gibt einen schematischen Überblick über den Aufbau der virtuellen Forschungsumgebung und das Zusammenspiel der Teilprojekte. Der virtuelle Forschungsraum (VFR) eröffnet Wissenschaftlerinnen und Wissenschaftlern einen digitalen Zugang zu den Sammlungen der drei Verbundeinrichtungen und bietet interaktive computergestützte Arbeitsmöglichkeiten für methodisch neue Forschungsperspektiven an. Damit dient der Forschungsraum als digitales Zugangs- und Arbeitsportal zu den Forschungsprojekten des Verbunds und den Verbundeinrichtungen selbst. Langfristig soll der virtuelle Forschungsraum zu einem universellen Rechercheinstrument und „Arbeitsplatz“ für die internationale geistes- und kulturwissenschaftliche Forschung ausgebaut werden.
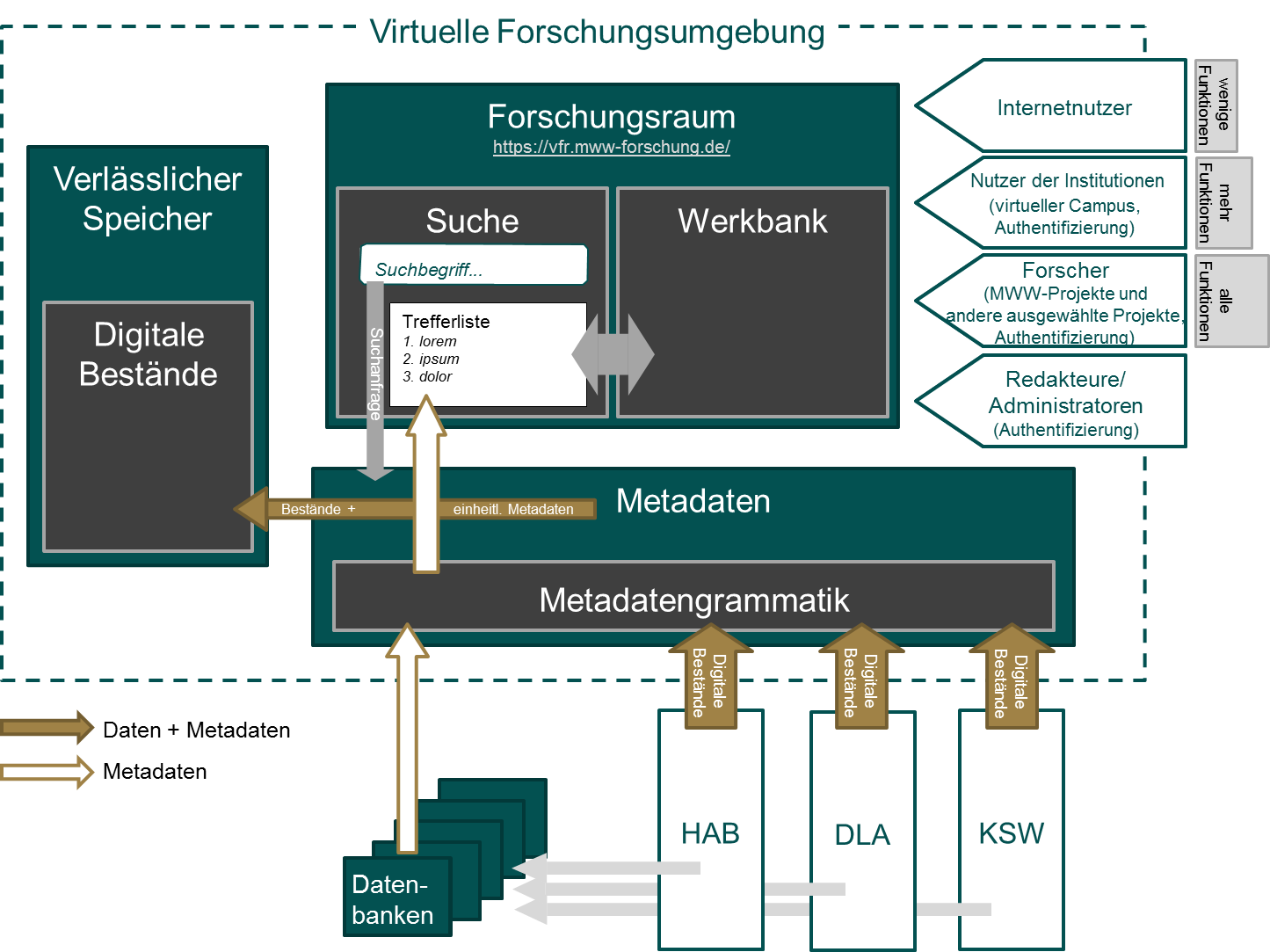 Der kollaborative Aufbau von digitaler Infrastruktur und die Erstellung eines gemeinsamen Forschungsdatenpools erfordern eine umfassende Analyse der Arbeitsprozesse, der vorhandenen Datensammlungen sowie der bereits genutzten Infrastruktur bezüglich der Dokumentation von Angaben zu Rechten und Lizenzen.
Der kollaborative Aufbau von digitaler Infrastruktur und die Erstellung eines gemeinsamen Forschungsdatenpools erfordern eine umfassende Analyse der Arbeitsprozesse, der vorhandenen Datensammlungen sowie der bereits genutzten Infrastruktur bezüglich der Dokumentation von Angaben zu Rechten und Lizenzen.
Durch die Ergebnisse konnten Muster erkannt werden, aufgrund derer sich Lösungen und Handlungsempfehlungen ableiten lassen, die bereits in ersten Ansätzen umgesetzt wurden. Der Beitrag und die Analyse widmen sich hauptsächlich den Digitalisaten und Erschließungsdaten der drei beteiligten Institutionen. Die Einbeziehung anderer Forschungsdaten und -ergebnisse in digitaler Form kann aufgrund der vorhandenen Vielfalt nur punktuell erfolgen.
Ergebnisse der Analyse
Das Verhältnis von Objekten und digitalen Repräsentationen ist kompliziert: n-Objekte haben m-digitale Aufnahmen.
Datenbankmanagementsysteme zur Erfassung und Erschließung von Beständen aus Bibliotheken, Archiven und Museen dienen ursprünglich vielen Zwecken: als Eigentumsnachweis (zum Beispiel Inventarisierung in Museen) oder um Nutzerinnen und Nutzern den Zugang zu Informationen zu ermöglichen (zum Beispiel Katalogisierung von Medien in Bibliotheken). Inventarnummern oder Signaturen beziehen sich auf einzelne Einheiten, die wiederum mit einer Vielzahl von digitalen Aufnahmen verknüpft sein können. Ebenso können Aufnahmen mehrere dokumentarische Bezugseinheiten abbilden (zum Beispiel die Fotodokumentation einer Ausstellungssituation mit mehreren Objekten).
Während die Dokumentation von Beständen und die Bereitstellung (digitaler) Kopien an den Institutionen an getrennten Stellen erfolgt, sollen die Erfassungssysteme zunehmend auch die Aufgaben von Systemen klassischer Bildagenturen übernehmen: die Verwaltung von Bildrechten, die Bereitstellung der Digitalisate auf Nutzerwunsch und im besten Fall noch die Unterstützung von Abrechnungsworkflows. Dass dies durch die erwähnten vielfältigen Beziehungen zwischen dokumentarischer Bezugseinheit und digitalen Aufnahmen eine größere Herausforderung darstellt, wird von Anbietenden der Erfassungssysteme und Softwarepakete zur Unterstützung von Digitalisierungsworkflows gern relativiert.
Die Integration von „Altdaten“ birgt besondere Herausforderungen.
Während bei der heutigen Erzeugung von Daten die Dokumentation von Informationen zu Rechten strukturiert und im besten Fall standardisiert erfolgt, folgen die Angaben bei „Altdaten“ unbekannten oder nicht ausreichend dokumentierten Regeln. Dies lässt sich auch dadurch erklären, dass zum Beispiel Forschungsdaten aus Projekten in einigen Fällen nicht für eine übergreifende Publikation im Web gedacht waren. Hier ist eine Ergänzung und Anreicherung in Abstimmung mit den Sammlungsverantwortlichen und inhaltlichen Ansprechpersonen nötig.
Auf Sammlungsebene kann dies durch eine Komponente der gGenerischen Suche erfolgen, die ein bestandsübergreifendes Recherchieren ermöglicht. In der Collection Registry werden einzelne Datensammlungen technisch und inhaltlich beschrieben.[2] Auch hier ist darauf zu achten, auf welche dokumentarische Bezugseinheit sich Lizenzangaben beziehen: Sind es die Digitalisate, angereicherte Erschließungsdaten oder Forschungsergebnisse?
Dokumentationsebenen analysieren
Entscheidungen, die auf unterschiedlichen Ebenen getroffen werden, haben Einfluss auf Rechte- und Lizenzangaben. Zur Vereinfachung wurden die Ebenen Institution, Sammlung, Objekt (Inventarnummer, Signatur) und Einzelaufnahme (einzelne Bilddatei) betrachtet:
Institution: Aufgrund der unterschiedlichen Bewertung rechtlicher Situationen treffen die beteiligten Institutionen auf einer hierarchisch hohen Ebene Entscheidungen, die Einfluss auf alle folgenden Ebenen haben. Dies kann zum Beispiel durch die Auswahl der Digitalisierungstechnik oder durch die Bewertung der Schöpfungshöhe bei der Erzeugung von Digitalisaten erfolgen.
Sammlung: Ein durch ein oder mehrere Merkmale abgrenzbarer Teil des Bestandes weist aufgrund seiner Art des Zusammenhalts eine Besonderheit für Rechte und Lizenzen auf, es könnte sich zum Beispiel um den Vorlass einer Schriftstellerin handeln, der aufgrund vertraglicher Bestimmungen besondere Bedingungen für die entstehenden Digitalisate aufweist.
Objekt: Ein einzelnes physisches Objekt bestimmt Rechte und Lizenzen der digitalen Aufnahmen, da es sich zum Beispiel um ein Möbel handelt, dessen Entwurf gewerbliche Schutzrechte enthält, die in den Metadaten aller verknüpften Digitalisate festgehalten werden sollten.
Einzelaufnahme: Auf der untersten Ebene, der Einzelaufnahme, könnte der Entstehungsprozess Einfluss auf Angaben zu einem Rechteinhaber enthalten, wenn es sich um eine Auftragsarbeit einer externen Fotografin oder eines Fotografen handelt. Die vertraglichen Bestimmungen geben vor, welche Rechte übertragen werden oder ob eine Namensnennung der Fotografin oder des Fotografen erforderlich ist.
Alle getroffenen Entscheidungen müssen beim Aufbau eines interoperablen Datenpools, der mithilfe einer gemeinsamen Forschungsinfrastruktur bereitgestellt wird, bedacht werden. Beim Ergänzen oder Anreichern der Metadaten mit rechtlichen Informationen sind die verschiedenen Ebenen der Dokumentation zu bedenken und gegebenenfalls entstehende Widersprüche aufzulösen.
Die Rolle der Institution im Prozess (Gebende oder Nehmende) beeinflusst das Entscheidungsverhalten.
Das in Kulturerbeinstitutionen verbreitete Vorgehen, sehr detaillierte Zitiervorgaben für Digitalisate gemeinfreier Werke mit dem Hinweis auf ein Urheberrecht festzulegen, wird auch bei den beteiligten Institutionen gepflegt. Für die Nutzerinnen und Nutzer sind die Entstehungsprozesse der Aufnahmen nicht dokumentiert, eine Schöpfungshöhe kann nicht ohne weiteren Rechercheaufwand ermittelt werden. Agiert die Institution als Nutzerin, weil sie zum Beispiel Digitalisate gemeinfreier Werke anderer Institutionen in Visualisierungen einbinden möchte, ist die Einschätzung möglicher Schutzrechte situationsbedingt liberaler.
Veränderungen der Arbeitsweise tragen zu heterogeneren Datenbeständen bei und erhöhen die Datenmenge.
Die digitalen Bestände werden aus Datensicht heterogener, da neue digitale Möglichkeiten neue Formate hervorrufen (wie zum Beispiel dreidimensionale Objekte). Auch Arbeitsdatenbanken die zur internen Sammlung und Strukturierung von Informationen erstellt wurden, werden bereitgestellt und müssen hinsichtlich der Dokumentation von Rechten gesondert betrachtet werden.
Die Datenmenge der Kulturerbeinstitutionen steigt aufgrund von technischen Entwicklungen und Prozessoptimierungen rascher an und stellt so die Forscherinnen und Forscher und Institutionen vor neue Aufgaben. Während in der Vergangenheit vor allem die Ergebnisse bestandsbezogener Forschung an Bibliotheken, Museen und Archiven digital aufbereitet und präsentiert wurden, rücken zunehmend auch Forschungsdaten und Ergebnisse digitaler Analyseverfahren in den Fokus der Publikation[3] und erhöhen die Menge des zu kuratierenden Datenmaterials.
In der Vergangenheit führten notwendige Zwischenschritte zur Aufbereitung der Forschungsergebnisse für eine digitale Präsentation zu einer Reduktion und Homogenisierung des Datenmaterials und erleichterten somit unter anderem die Dokumentation der Rechte und die Entscheidungen hinsichtlich möglicher Optionen der Lizenzierung.
An unterschiedlichen Stellen entstehen in einer Institution aus verschiedenen Gründen Digitalisate.
Eine erste Einschätzung ergab, dass in jeder Institution Digitalisate an einer zentralen Stelle erzeugt werden. Somit wäre auch die Dokumentation von Rechten an dieser zu verorten. Nach einer Analyse des Datenbestands ergab sich jedoch ein vielfältigeres Bild: Alle, die an Beständen forschen, erzeugen beiläufig Digitalisate (zum Beispiel Schadensdokumentation eines Restaurators, Fotodokumentation einer Ausstellung, Detailaufnahmen für eine Publikation mit besonderem Fokus). Diese werden in einigen Fällen zunächst ohne zusätzliche Metadaten abgelegt und tauchen in Forschungsprojekten wieder auf. Eine nachträgliche Anreicherung muss (wie bei den „Altdaten“) in Absprache mit den Sammlungsverantwortlichen und inhaltlichen Ansprechpersonen erfolgen.
Lösungsansätze und Handlungsempfehlungen
Analyse der aufgebauten Infrastruktur: In welchen Bereichen spielen Angaben zu Rechten eine Rolle?
Eine Analyse der bereits aufgebauten Verbundinfrastruktur ergab, dass Angaben zu Rechten und Lizenzen zu Digitalisaten in vielen Bereichen der virtuellen Forschungsumgebung übernommen, verarbeitet und gespeichert werden.
Jeder angebotene Service, der für die Weiterverarbeitung, Anreicherung oder Analyse von Digitalisaten und ihrer Metadaten verwendet wird, benötigt einen standardisierten Input. Die Rechteinformationen der Ursprungsdaten müssen in sämtliche folgende Forschungsprozesse übernommen werden. Hier spielen die Übergabepunkte zwischen den Services eine wichtige Rolle.
Rechte-Informationen auf Sammlungsebene verwalten
Die in der Abbildung „Vereinfachte Architekturskizze der MWW-Forschungsinfrastruktur“ dargestellte Suchfunktion wird mit der an der Universität Bamberg im Rahmen von DARIAH-DE entwickelten Generischen Suche realisiert und als Service für eine bestandsübergreifende Recherche im virtuellen Forschungsraum integriert. Hier erfüllt sie einerseits den Bedarf aus Sicht der Nutzerinnen und Nutzer, heterogene Bestände zu durchsuchen und ermöglicht interessierten Forscherinnen und Forscher einen Einstieg auf Sammlungsebene. Zudem bietet die Generische Suche mit der Collection Registry eine Komponente, um sammlungsbeschreibende Daten standardisiert zu erfassen und zu verwalten. Somit konnte der analysierte Bedarf einer Dokumentation aus Sammlungsebene bereits umgesetzt werden. Sofern keine widersprüchlichen Aussagen zu erwarten sind, ist eine Dokumentation der Rechteinformationen auf einer hohen Ebene anzustreben, um den Aufwand der Datenpflege gering zu halten.
Identifizierung des Beratungsbedarfs der Forscher an den Institutionen und die Umsetzung im virtuellen Forschungsraum.
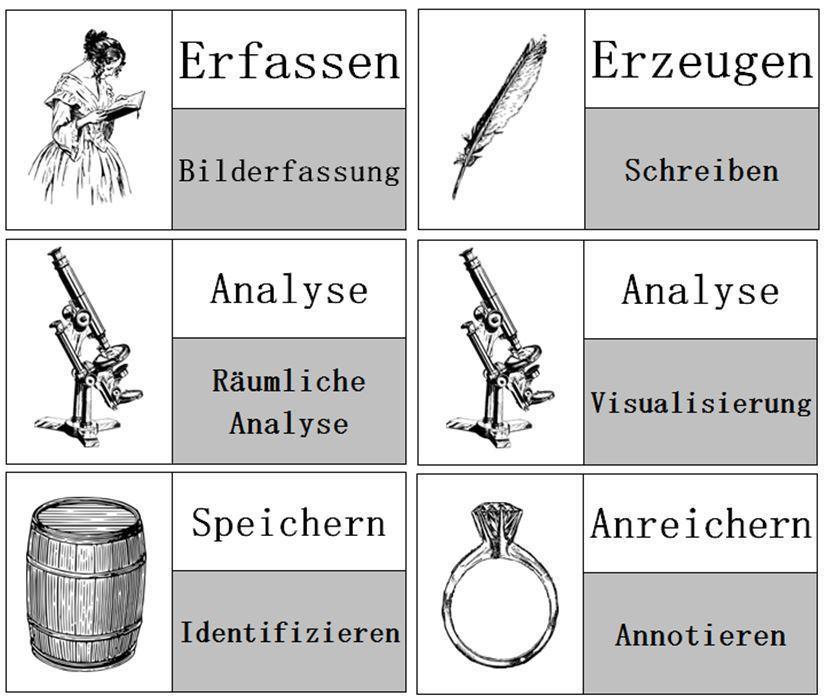 Der Aufbau der projektspezifischen LABs im virtuellen Forschungsraum orientiert sich an TaDiRAH[4], einer anwendungsorientierten Taxonomie zur Klassifikation von Ressourcen und Services im Bereich der Digital Humanities. Jedes Forscherteam wird bereits in einer frühen Planungsphase beim Forschungsdatenmanagement begleitet und richtet gemeinsam mit den Mitarbeiterinnen und Mitarbeitern aus dem Team Digitale Infrastruktur projektspezifische LABs ein (siehe Abbildung „Projektplanung nach TaDiRAH“).
Der Aufbau der projektspezifischen LABs im virtuellen Forschungsraum orientiert sich an TaDiRAH[4], einer anwendungsorientierten Taxonomie zur Klassifikation von Ressourcen und Services im Bereich der Digital Humanities. Jedes Forscherteam wird bereits in einer frühen Planungsphase beim Forschungsdatenmanagement begleitet und richtet gemeinsam mit den Mitarbeiterinnen und Mitarbeitern aus dem Team Digitale Infrastruktur projektspezifische LABs ein (siehe Abbildung „Projektplanung nach TaDiRAH“).
Im Zuge der Bedarfsermittlung der Nutzerinnen und Nutzer zum Aufbau eines virtuellen Forschungsraums konnte eine neue Anforderung identifiziert werden: die Beratung von bestandsbezogenen Forschungsprojekten hinsichtlich rechtlicher Besonderheiten bei der Einbindung von Digitalisaten und Forschungsdaten externer Institutionen.
Gemeinschaft braucht Standards und gibt neue Impulse
Um eine Interoperabilität der Daten in einer Verbundarchitektur zu gewährleisten, ist die Verwendung von Standards von zentraler Bedeutung, auch bei der Lizenzierung von erzeugten Daten, Digitalisaten und Forschungsergebnissen ist eine eindeutige Dokumentation für eine Nachnutzbarkeit wichtig.
Die Idee eines abgestimmten Sets an Lizenzen ist aus anderen institutionsübergreifenden Projekten bekannt, wünschenswert wäre ein kleines Set an Lizenzvarianten – wie es den Nutzerinnen und Nutzern zum Beispiel aus der Elektronischen Zeitschriftenbibliothek vertraut ist. Dies sollte sich an den gegebenenfalls in den Häusern bereits üblichen Verfahren orientieren und dann den Sammlungsbetreuenden vorgestellt werden, um die Daten in die Generische Suche und damit auch im virtuellen Forschungsraum zur Verfügung zu stellen.
Während beim Teilen von Daten die Informationen zu Rechten möglichst standardisiert erfolgen sollte, sind in den internen Erfassungssystemen weiterführende Angaben hilfreich, die im Einzelfall zu einer bestimmten Lizenzierung führten (zum Beispiel der Verweis auf den Vertrag mit der externen Fotografin oder dem externen Fotografen).
Das beobachtete Zusammenführen von der Dokumentation der Bestände und der Dokumentation von verknüpften Digitalisaten in einem System ist zu prüfen. Die Einrichtung von Schnittstellen, um im Falle eines Exports (in den virtuellen Forschungsraum oder in externe Portale) Informationen aus verschiedenen Quellen zusammenzuführen, ermöglicht eine saubere Trennung der unterschiedlichen dokumentarischen Bezugseinheiten.
Prinzipien der Open-Science-Bewegung spielen beim Aufbau der gemeinsamen Infrastruktur eine zunehmend wichtige Rolle. Der Forschungsverbund Marbach Weimar Wolfenbüttel gibt mit der Zeitschrift für digitale Geisteswissenschaften[5] ein Open Access Journal heraus, nutzt beim Aufbau der Infrastruktur Open-Source-Produkte und stellt Weiterentwicklungen der Community zur Verfügung. Auch Forscherinnen und Forscher sehen die Vorteile von Open Data in ihrer datengestützten bestandsorientierten Arbeit, wenn zum Beispiel die Einbindung „fremder“ Digitalisate für Visualisierungen erforderlich ist. Der Forschungsverbund kann hier somit auf verschiedenen Ebenen in den beteiligten Institutionen Impulse geben, die bestehenden Restriktionen, Vorbehalte oder Hindernisse in der Weiterverwendung von Daten, Digitalisaten und Forschungsergebnissen abzubauen.
Anmerkungen
[1] Näheres auf <mww.forschung.de> und <https://vfr.mww-forschung.de>.
[2] Eine ausführliche Beschreibung ist im Wiki von DARIAH-DE nachzulesen: <https://wiki.de.dariah.eu/display/publicde/Die+Collection+Registry>.
[3] Siehe hierzu unter anderem die DFG-Leitlinien zum Umgang mit Forschungsdaten von 2015 <http://www.dfg.de/download/pdf/foerderung/antragstellung/forschungsdaten/richtlinien_forschungsdaten.pdf)> und die Grundsätze zum Umgang mit Forschungsdaten der Allianz der deutschen Wissenschaftsorganisationen von 2010 <https://www.allianzinitiative.de/de/archiv/forschungsdaten/grundsaetze.html)>.
[4] Siehe <http://tadirah.dariah.eu/>, eine deutsche Fassung ist hier zu finden: <https://github.com/dhtaxonomy/TaDiRAH/tree/master/deu>.
[5] Siehe <www.zfdg.de>